Unlocking the Power of Big Data: A Comprehensive Guide to MapReduce with Python
Related Articles: Unlocking the Power of Big Data: A Comprehensive Guide to MapReduce with Python
Introduction
With great pleasure, we will explore the intriguing topic related to Unlocking the Power of Big Data: A Comprehensive Guide to MapReduce with Python. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Unlocking the Power of Big Data: A Comprehensive Guide to MapReduce with Python
- 2 Introduction
- 3 Unlocking the Power of Big Data: A Comprehensive Guide to MapReduce with Python
- 3.1 Understanding the MapReduce Paradigm
- 3.2 Python and MapReduce: A Perfect Pairing
- 3.3 Illustrative Example: Word Count with MapReduce
- 3.4 Benefits of MapReduce with Python
- 3.5 FAQs on MapReduce with Python
- 3.6 Tips for Implementing MapReduce with Python
- 3.7 Conclusion
- 4 Closure
Unlocking the Power of Big Data: A Comprehensive Guide to MapReduce with Python

In the era of big data, where datasets grow exponentially, processing and analyzing information efficiently becomes paramount. Enter MapReduce, a powerful programming model designed to handle massive amounts of data distributed across multiple computers. This model, widely adopted for its scalability and efficiency, enables the processing of data in parallel, leveraging the collective power of multiple machines. Python, with its intuitive syntax and rich libraries, provides a suitable environment for implementing MapReduce, empowering developers to tackle complex data challenges.
Understanding the MapReduce Paradigm
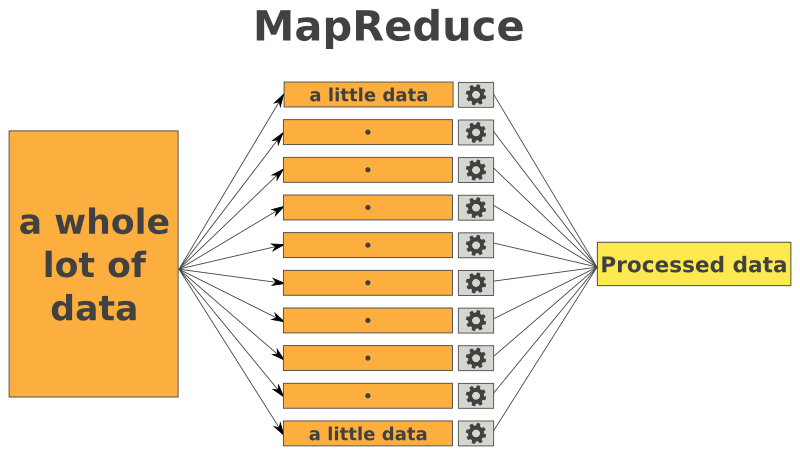
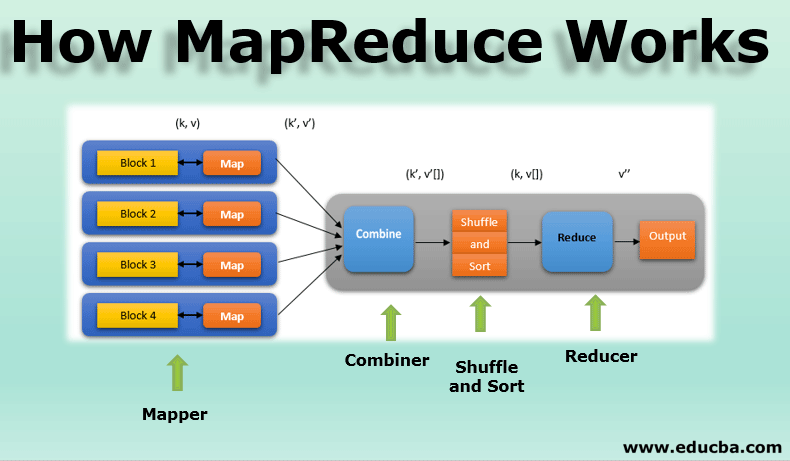
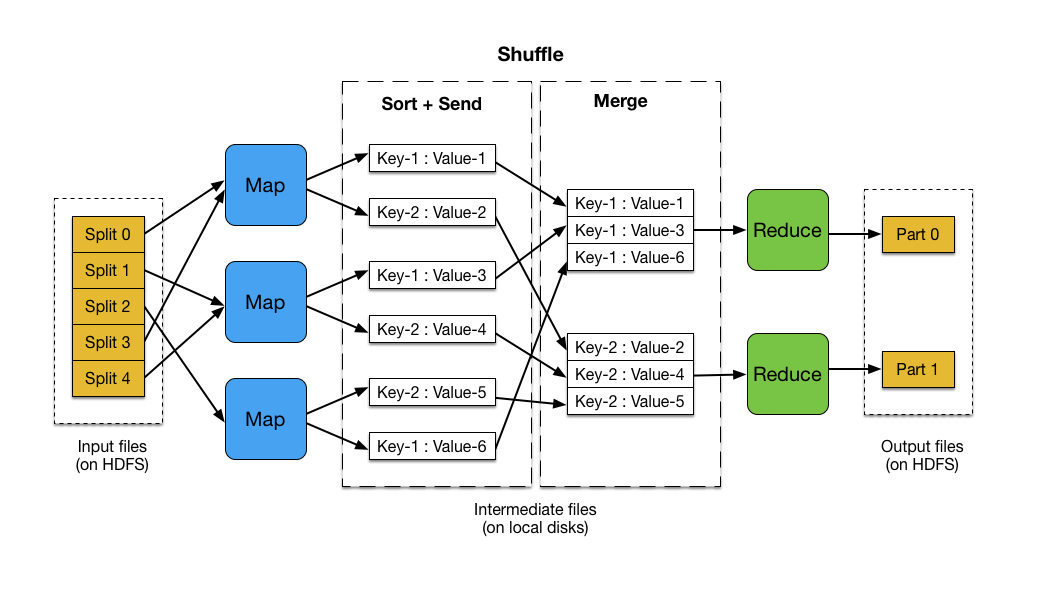
At its core, MapReduce is a two-phase process, aptly named for its key operations:
1. Map Phase: This phase involves transforming the input data into key-value pairs. The "map" function, defined by the programmer, iterates through each data element, extracting relevant information and generating a key-value pair for each. The key acts as a grouping mechanism, ensuring that values associated with the same key are processed together in the subsequent phase.
2. Reduce Phase: The "reduce" function takes the output of the map phase, grouping values associated with the same key and applying a specific aggregation function to these groups. This function can perform operations such as summation, counting, or averaging, depending on the desired analysis.
Python and MapReduce: A Perfect Pairing
Python, with its clear syntax and robust libraries, offers a convenient and efficient platform for implementing MapReduce. Libraries such as mrjob and dask provide pre-built functionalities for creating and executing MapReduce jobs, simplifying the development process.
1. Mrjob: This library streamlines the development and execution of MapReduce jobs. It allows for defining map and reduce functions in Python, and automatically handles the distribution of data across multiple machines. The mrjob library also facilitates the management of input and output data, making it a valuable tool for data processing at scale.
2. Dask: While not explicitly designed for MapReduce, Dask offers a powerful framework for distributed computing, including support for parallel data processing. Dask provides a high-level interface for defining parallel operations, enabling the execution of MapReduce-like workflows on a cluster of machines.
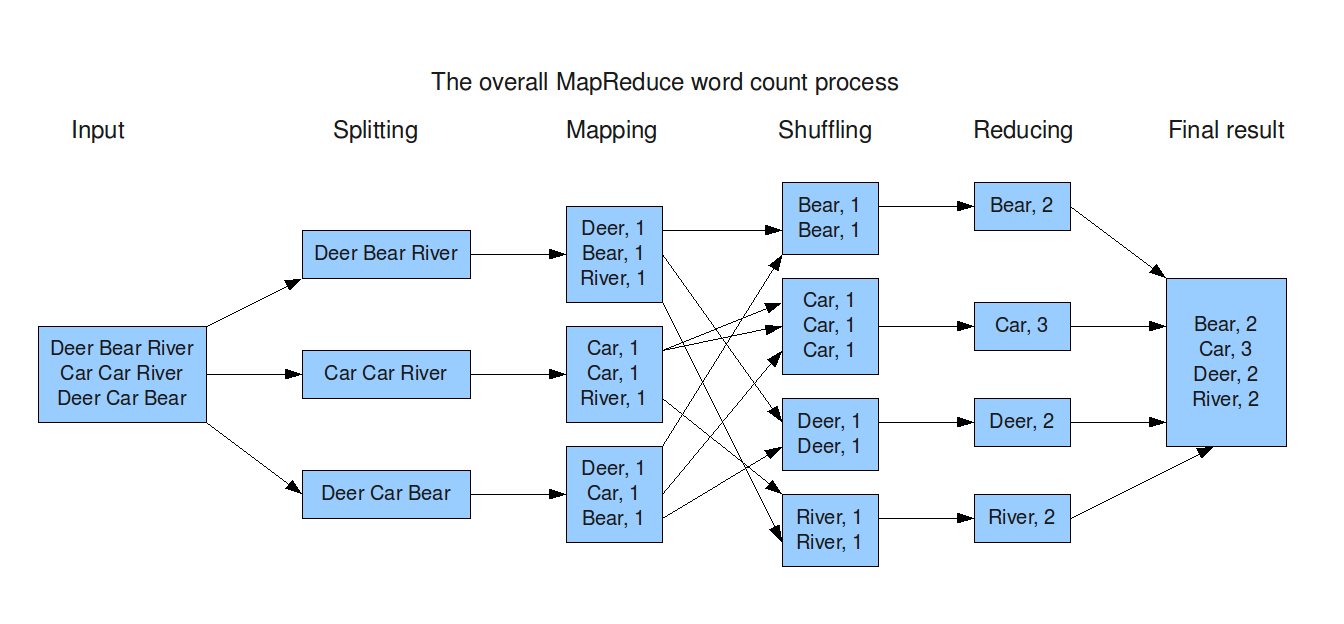
Illustrative Example: Word Count with MapReduce
Let’s consider a simple example to illustrate the MapReduce process using Python and the mrjob library:
Problem: Count the frequency of words in a text file.
Solution:
from mrjob.job import MRJob
class WordCount(MRJob):
def mapper(self, _, line):
for word in line.split():
yield word, 1
def reducer(self, word, counts):
yield word, sum(counts)
if __name__ == '__main__':
WordCount.run()Explanation:
- The
WordCountclass inherits fromMRJob, providing the necessary structure for a MapReduce job. - The
mapperfunction iterates through each line in the input file, splitting it into words. For each word, it emits a key-value pair, where the key is the word itself and the value is 1 (representing a single occurrence). - The
reducerfunction receives all values associated with the same key (word) and sums them, producing the final word count.
This simple example showcases the power of MapReduce in efficiently processing large datasets. The parallel nature of the process allows for significant speedups compared to traditional sequential processing methods.
Benefits of MapReduce with Python
The combination of MapReduce and Python offers several advantages for big data processing:
1. Scalability: MapReduce is inherently scalable, allowing for processing data across multiple machines. As the data size grows, the processing power can be scaled linearly by adding more nodes to the cluster.
2. Fault Tolerance: MapReduce is designed to be resilient to failures. If a node in the cluster fails, the job can continue running on the remaining nodes, ensuring data integrity and processing continuity.
3. Simplicity: Python’s clear syntax and the availability of libraries like mrjob simplify the development of MapReduce jobs. The abstraction provided by these libraries allows developers to focus on the core logic of the map and reduce functions, without needing to worry about the complexities of distributed computing.
4. Versatility: MapReduce is a versatile model applicable to a wide range of data processing tasks, including text analysis, web log processing, and machine learning.
FAQs on MapReduce with Python
1. How does MapReduce handle data distribution?
MapReduce frameworks automatically handle data distribution, dividing the input data into chunks and distributing them across different nodes in the cluster. This ensures parallel processing and efficient utilization of resources.
2. What are the key differences between mrjob and dask?
mrjob is specifically designed for MapReduce jobs, providing a streamlined interface for defining map and reduce functions and managing data distribution. dask, while not explicitly for MapReduce, offers a more general framework for distributed computing, allowing for flexible data processing workflows.
3. How does MapReduce handle data shuffling?
After the map phase, the key-value pairs are shuffled and grouped based on the key. This process ensures that all values associated with the same key are sent to the same reducer, facilitating efficient aggregation.
4. What are the limitations of MapReduce?
MapReduce is primarily suited for batch processing of large datasets. It may not be ideal for real-time data processing or tasks requiring complex data dependencies.
Tips for Implementing MapReduce with Python
1. Optimize Map and Reduce Functions: Carefully design the map and reduce functions to maximize efficiency. Aim for concise and optimized logic to minimize processing time.
2. Leverage Libraries: Utilize libraries like mrjob or dask to simplify the development process. These libraries provide pre-built functionalities and handle the complexities of distributed computing.
3. Monitor Job Execution: Monitor the execution of MapReduce jobs to identify bottlenecks and optimize performance. Tools like mrjob provide monitoring capabilities for tracking progress and identifying potential issues.
4. Understand Data Partitioning: Consider the distribution of data across nodes to ensure balanced workloads and efficient processing.
Conclusion
MapReduce, combined with the power of Python, provides a robust and efficient solution for processing large datasets. Its inherent scalability, fault tolerance, and simplicity make it a valuable tool for tackling complex data challenges. By understanding the core principles of MapReduce and leveraging the available libraries, developers can harness the power of distributed computing to unlock valuable insights from massive datasets, driving innovation and decision-making in various domains.



![2. MapReduce with Python - Hadoop with Python [Book]](https://www.oreilly.com/api/v2/epubs/9781492048435/files/assets/hdpy_0201.png)
Closure
Thus, we hope this article has provided valuable insights into Unlocking the Power of Big Data: A Comprehensive Guide to MapReduce with Python. We hope you find this article informative and beneficial. See you in our next article!